
¿Qué es el control de versiones, y por qué debería ser importarte? El control de versiones es un sistema que registra los cambios realizados sobre un archivo o conjunto de archivos a lo largo del tiempo, de modo que el usuario pueda recuperar versiones específicas más adelante. A pesar de que los ejemplos de este informe muestran código fuente como archivos bajo control de versiones, en realidad cualquier tipo de archivo que se encuentre en un ordenador puede ponerse bajo control de versiones.[1]
Una herramienta de la que muchas personas, sean diseñadores gráficos o web pueden hacer uso y es de muy buena calidad es la llamada Version Control System (VCS). Con esta herramienta es posible revertir archivos a un estado anterior, revertir el proyecto entero a un estado anterior, comparar cambios a lo largo del tiempo, ver quién modificó por última vez algo que puede estar causando un problema, quién introdujo un error y cuándo, y mucho más. Usar un VCS también significa generalmente que si fastidias o pierdes archivos, puedes recuperarlos fácilmente. Además, obtienes todos estos beneficios a un coste muy bajo.
Un método de control de versiones usado por mucha gente es copiar los archivos a otro directorio (quizás indicando la fecha y hora en que lo hicieron, si son avispados). Este enfoque es muy común porque es muy simple, pero también está propenso a errores. Es fácil olvidar en qué directorio se encuentra en el momento en que se encuentra trabajando, y guardar accidentalmente en el archivo equivocado o sobrescribir archivos que no se estaba pensado hacer.
Para hacer frente al problema anterior, los programadores desarrollaron VCSs locales que contenían una simple base de datos en la que se llevaba registro de todos los cambios realizados sobre los archivos como se muestra en la siguiente imagen.
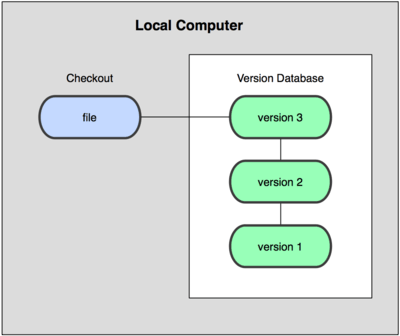
El siguiente gran problema en el que se encuentran las personas es que necesitan colaborar con desarrolladores en otros sistemas diferentes. Para resolver este problema, se desarrollaron los Centralized Version Control Systems (CVCSs). Estos sistemas, como CVS, Subversion, y Perforce, tienen un único servidor que contiene todos los archivos versionados, y varios clientes que descargan los archivos desde ese lugar central. Para que la idea quede un poco más clara se muestra la siguiente imagen.
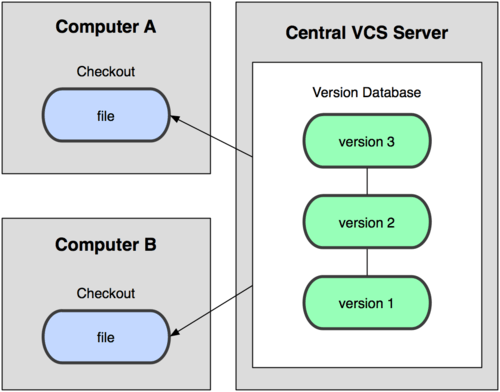
Esta configuración ofrece muchas ventajas, especialmente frente a VCSs locales. Por ejemplo, cualquier persona puede saber (hasta cierto punto) en qué están trabajando los otros colaboradores del proyecto. Los administradores tienen control detallado de qué puede hacer cada uno; y es mucho más fácil administrar un CVCS que tener que lidiar con bases de datos locales en cada cliente.
Sin embargo, esta configuración también tiene serias desventajas. La más obvia es el punto único de fallo que representa el servidor centralizado. Si ese servidor se cae durante una hora, entonces durante esa hora nadie puede colaborar o guardar cambios versionados de aquello en que están trabajando. [1]
Sistemas de control de versiones distribuidos
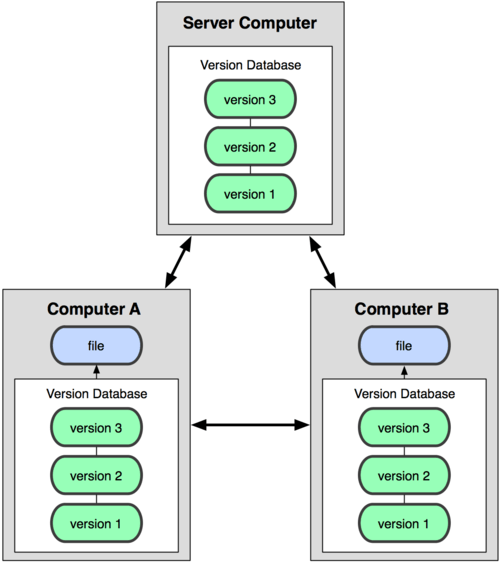
Es aquí donde entran los Distributed Version Control Systems (DVCSs). En un DVCS (como Git, Mercurial, Bazaar o Darcs), los clientes no sólo descargan la última instantánea de los archivos: replican completamente el repositorio. Así, si un servidor muere, y estos sistemas estaban colaborando a través de él, cualquiera de los repositorios de los clientes puede copiarse en el servidor para restaurarlo. Cada vez que se descarga una instantánea, en realidad se hace una copia de seguridad completa de todos los datos como se puede visualizar en la siguiente imagen.
Referencias:






